
[�n�̺���]������(j��)�h����͇���Ժ����(li��n)�W(w��ng)+���Є�Ӌ����(zh��n)�Բ��֣��䌍����Ժ���M��(sh��)��(j��)�l(f��)չ�ЄӾVҪ��푑����I(y��)����Ϣ�������B(y��ng)��(sh��)��(j��)���g�߶��˲ŵ�̖��,�Ї���Ϣ����Ӗ�������Ƴ��˴�(sh��)��(j��)ƽ�_��c������Ӌ�㌍��(zh��n)�n����Ӗ�ࡣ ...
| ���r�g���c�� | 2017��12��15-18�� ���� | ||
| ����Ӗ�v���� | �����v�� | ||
| �����ӌ��� | ���� | ||
| �������M�á� | ��5800Ԫ/�� ���������M����ԇ�C���M���̲��M���W�����g������M�� ʳ�y(t��ng)һ���ţ��M��������Ո�W�T���������1��������ע���������������C��ӡ��һ�������n�̌W������ͨ�^�����Ї���Ϣ����Ӗ�����C�l(f��)����(sh��)��(j��)�_�l(f��)���ܘ������C��; �C�������錣�I(y��)���g�ˆT�I(y��)�������˵��C�����Լ����I(y��)���g�ˆT��λƸ�á����������͕x���յ���Ҫ����(j��)�� | ||
| �����սM���� | ɭ����Ӗ�W(w��ng)��www.gzlkec.com�����V��������I(y��)������ԃ����˾ | ||
| ����ԃ�Ԓ�� | 020-34071250��020-34071978����ǰ���������ܸ�����(y��u)�ݣ� | ||
| ��(li��n) ϵ �ˡ� | ����������С�㣻13378458028��18924110388�����ɼ��ţ� | ||
| ���ھ� QQ �� | 568499978 |  �n�V���d �n�V���d |
 |
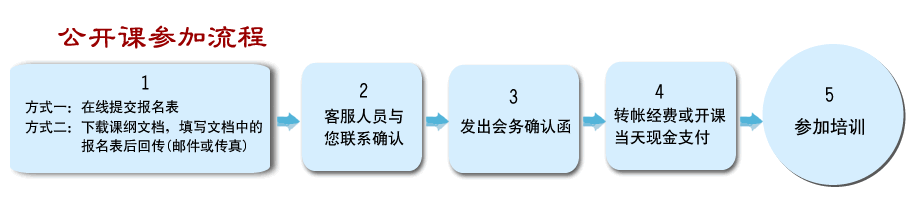
| ����ܰ��ʾ�� | ���n�̿����M����I(y��)��(n��i)����Ӗ���gӭ����A�s�� | ||
����(j��)�h����͇���Ժ����(li��n)�W(w��ng)+���Є�Ӌ����(zh��n)�Բ��֣��䌍����Ժ���M��(sh��)��(j��)�l(f��)չ�ЄӾVҪ��푑����I(y��)����Ϣ�������B(y��ng)��(sh��)��(j��)���g�߶��˲ŵ�̖��,�Ї���Ϣ����Ӗ�������Ƴ��˴�(sh��)��(j��)ƽ�_��c������Ӌ�㌍��(zh��n)�n����Ӗ�ࡣͨ�^���I(y��)�Ĵ�(sh��)��(j��)���g�ܘ��wϵ�c�I(y��)���挍������ȫ��������(sh��)��(j��)�Ŀ�߹ܡ���(sh��)��(j��)ƽ�_�ܘ������Լ���(sh��)��(j��)�_�l(f��)���̎��c��(sh��)��(j��)�����OӋ�ˆT�Č��I(y��)ˮƽ��ּ�����B(y��ng)���I(y��)�Ĵ�(sh��)��(j��)���g�ܘ����ң����B(y��ng)��(sh��)��(j��)���g�͑��Ä�(chu��ng)�����˲ţ����M��(sh��)��(j��)���g�ڸ��ИI(y��)��(n��i)�������ИI(y��)�M�Ќ�ʩ���ã��Լ����I(y��)��λ�Ĵ�(sh��)��(j��)�Ŀ�_�l(f��)����أ������ô�(sh��)��(j��)������������(y��u)�ݡ�
һ�� ��Ӗ��ɫ
1. �n����Ӗ�I(y��)�������С�������V����Hadoop�cSpark��(sh��)��(j��)���g�wϵ��
������(sh��)��(j��)ƽ�_�ķֲ�ʽ��Ⱥ�ܘ��ͺ����P�I���g���F(xi��n)����(sh��)��(j��)�����Ŀ�_�l(f��)�ʹ�(sh��)��(j��)��Ⱥ�\�S���`���Լ�Hadoop�cSpark��(sh��)��(j��)�Ŀ�����_�l(f��)�c�{(di��o)��(y��u)��ȫ�^��ɳ�Pģ�M����(zh��n)��
2. ͨ�^һ�������Ĵ�(sh��)��(j��)�_�l(f��)�Ŀ��һ�M���H�ĿӖ����������ȫ���wHadoop�cSpark���B(t��i)ϵ�y(t��ng)ƽ�_�đ����_�l(f��)�c�\�S���`���n�Ì��`�Ŀ���ĿС�M����ʽ�M��ɳ�P���پ��������c��������Hadoop�cSpark��(sh��)��(j��)�Ŀ�����A�εĹ������c��ͬ�r���������(sh��)��(j��)�Ŀ�����ߵĻ������g�c�I(y��)�����B(y��ng)��
3. ���n�̵����n���Y��������������һ������Hadoop�cSpark��(sh��)��(j��)�Ŀ���Y���v��������ԭ�����g�����͌���(zh��n)������Y�ϵķ�ʽ�_չ���ӽ̌W�������Խ�����(sh��)��(j��)�Ŀ��Q���������w�đ����_�l(f��)�����gӑՓ�c������ԃ���ڌW����ͬ�r���M�v���W�T֮�g�Ľ�����ÿ���W�T�������n����Ӗ�^���ЌW���������ڵĴ�(sh��)��(j��)���g֪�R�wϵ���Լ���(sh��)��(j��)���g���Ì���(zh��n)���ܣ��߂䌍�H��(sh��)��(j��)�����Ŀ�Ą����_�l(f��)���`�c�\�S�����������������n�^���У�����(j��)�W�T�������O�����h(hu��n)��(ji��)���Ɍ����w�����������Č��H���}չ�_ӑՓ���v��������(j��)�W�T�Č��H��r�{(di��o)���n��(n��i)�ݣ����v������ȫ���W�T�e�OӑՓ�����o��һ���ĕr�g�W�T���_�l(f��)�ԣ��F(xi��n)���������}�İY�Y��Ҏ(gu��)�������еĽ�Q������
������ӖĿ��
1.��������ڡ���(li��n)�W(w��ng)+���r���´�(sh��)��(j��)�Įa(ch��n)���������l(f��)չ�v�̺��ݻ�څ�ݣ�
2.�˽�I(y��)���Ј�����͇���(n��i)�����µĴ�(sh��)��(j��)���g�����������(sh��)��(j��)�ĝ��ڃrֵ��
3.�����(sh��)��(j��)�Ŀ��Q�������I(y��)���(sh��)��(j��)���ð������Ķ�����I(y��)�ڴ�(sh��)��(j��)�Ŀ
�еļ��g�x�ͼ����g�ܘ��OӋ�ṩ�Q�߅�����
4.���I(y��)�������е�Hadoop�cSpark��(sh��)��(j��)���g�wϵ��
5.���մ�(sh��)��(j��)�ɼ����g��
6.���մ�(sh��)��(j��)�ֲ�ʽ�惦���g��
7.����NoSQL�cNewSQL�ֲ�ʽ��(sh��)��(j��)�켼�g��
8.���մ�(sh��)��(j��)�}���c�y(t��ng)Ӌ�C���W�����g��
9.���մ�(sh��)��(j��)�����ھ��c�̘I(y��)���ܣ�BI�����g��
10.���մ�(sh��)��(j��)�x��̎�����g��
11.����Storm��ʽ��(sh��)��(j��)̎�����g��
12.���ջ��ڃ�(n��i)��Ӌ��Ĵ�(sh��)��(j��)���r̎�����g��
13.���մ�(sh��)��(j��)�������g��ԭ��֪�R�͑��Ì���(zh��n)��
14.���������(sh��)��(j��)ƽ�_���g�ܘ���ʹ�È�����
15.�����\��Hadoop�cSpark��(sh��)��(j��)���g�wϵҎ(gu��)����Q�����M�㌍�H�Ŀ����
16.�쾚�����ջ���Hadoop�cSpark��(sh��)��(j��)ƽ�_�M�Б��ó����_�l(f��)����Ⱥ�\�S�����������{(di��o)��(y��u)���ɡ�
�����n�̴�V
��һ������
��(sh��)��(j��)���g���A
1. ��(sh��)��(j��)�Įa(ch��n)�������c�l(f��)չ�v��
2. ��(sh��)��(j��)��4V�������Լ��c��Ӌ����Pϵ
3. ��(sh��)��(j��)���������Լ����ڃrֵ����
4. �I(y��)�����µĴ�(sh��)��(j��)���g�l(f��)չ�B(t��i)���c����څ��
5. ��(sh��)��(j��)�Ŀ��ϵ�y(t��ng)�c���g�x�ͣ�����،�ʩ������(zh��n)
6. ����(li��n)�W(w��ng)+���r���µ�����̄ա�����I(y��)���������l(f��)������\�I�̡���(li��n)�W(w��ng)���ژI(y��)��������ա��Ƅӻ�(li��n)�W(w��ng)��������Ϣ�����ИI(y��)���Ì��`�c���ð�����B
�I(y��)�������Ĵ�(sh��)��(j��)���g���� 1. ��(sh��)��(j��)ܛӲ��ϵ�y(t��ng)ȫ���c�P�I���g��B
2. �����Ĵ�(sh��)��(j��)��Q������B
3. Apache��(sh��)��(j��)ƽ�_��������
4. CDH��(sh��)��(j��)ƽ�_��������
5. HDP��(sh��)��(j��)ƽ�_��������
6. ��(sh��)��(j��)��Q�����c���y(t��ng)��(sh��)��(j��)�췽�����^
��(sh��)��(j��)Ӌ��ģ�ͣ�һ��������̎��MapReduce
1. MapReduce�a(ch��n)�������c�m����
2. MapReduceӋ��ģ�͵Ļ���ԭ��
3. MapReduce���I(y��)��(zh��)������
4. MapReduce�����M����JobTracker��TaskTracker
5. MapReduce�����̑��ã�Combiner��Partitioner
6. MapReduce���܃�(y��u)������
7. MapReduce���������c�_�l(f��)���`����
��һ������
��(sh��)��(j��)�惦ϵ�y(t��ng)�c���Ì��`
1. �ֲ�ʽ�ļ�ϵ�y(t��ng)HDFS�a(ch��n)�������c�m�È���
2. HDFS master-slaveϵ�y(t��ng)�ܘ��c����ԭ��
3. HDFS���ĽM�����g�v��
4. HDFS�߿��ñ��C�C��
5. HDFS��Ⱥ�İ��b�������c���ã��쾚HDFS shell�������
6. �ֲ�ʽС�ļ��惦ϵ�y(t��ng)��ƽ�_�ܘ������ļ��g�c���È���
7. �ֲ�ʽ����惦ϵ�y(t��ng)��ƽ�_�ܘ������ļ��g�c���È���
Hadoop����c���B(t��i)�l(f��)չ���Լ����Ì��`���� 1. Hadoop�İl(f��)չ�v��
2. Hadoop��(sh��)��(j��)���B(t��i)Ȧϵ�y(t��ng)�c����ȫò��B
3. Hadoop 1.0�ĺ��ĽM���c�m�÷���
4. Hadoop 2.0�ĺ��ĽM��YARN����ԭ�����Լ��cHadoop 1.0�ą^(q��)�e
5. Hadoop�YԴ�����c���I(y��)�{(di��o)�șC��
6. Hadoop �������܃�(y��u)�����g
7. Hadoop��Ⱥ���b�c�������`���Լ�MapReduce������YARN�ψ�(zh��)��
�ڶ�������
��(sh��)��(j��)Ӌ��ģ�ͣ������������r̎��/��(n��i)��Ӌ�� Spark
1. MapReduceӋ��ģ�͵�ƿ�i
2. Spark�a(ch��n)���әC�����������c�m�È���
3. Spark����ģ���cRDD���Էֲ�ʽ��(sh��)��(j��)���Ĺ���ԭ���c�C��
4. Spark���r̎��ƽ�_�\�мܘ��c���ĽM��
5. Spark���e�C��
6. Spark���I(y��)�{(di��o)�șC��
7. Scala�_�l(f��)��B�c���`
8. Spark��Ⱥ�����c���Ì��`��Spark�_�l(f��)�h(hu��n)��������Spark�������������Spark�����_�l(f��)�c�\�У�Spark�cHadoop��Ⱥ���Ɍ��`
�ڶ�������
��(sh��)��(j��)�}���ԃ���gHive��SparkSQL��Impala���Լ����Ì��`
1. ����MapReduce�Ĵ��ͷֲ�ʽ��(sh��)��(j��)�}��Hive���A֪�R�c���È���
2. Hive��(sh��)��(j��)�}���ƽ�_�ܘ��c���ļ��g����
3. Hive metastore�����C���c����
4. Hive��(sh��)��(j��)�}�쌍�`��Hive��Ⱥ���b���𣬔�(sh��)��(j��)�}��팧�댧���c�օ^(q��)������Hive SQL������Hive�͑��˲���
5. ����Spark�Ĵ��ͷֲ�ʽ��(sh��)��(j��)�}��SparkSQL���A֪�R�c���È���
6. Spark SQL���r��(sh��)��(j��)�}��Č��F(xi��n)ԭ���c�����C��
7. SparkSQL���÷����c�������`
8. ����MPP�Ĵ��ͷֲ�ʽ��(sh��)��(j��)�}��Impala���A֪�R�c���È���
9. Impala���r��ԃϵ�y(t��ng)ƽ�_�ܘ����P�I���g����
Hadoop��Ⱥ�\�S�O(ji��n)�ع���
1. Hadoop��(sh��)��(j��)�\�S�O(ji��n)�ع���ϵ�y(t��ng)HUEƽ�_��B
2. Hadoop�\�S�����O(ji��n)��ϵ�y(t��ng)Ambari���߽�B
3. �������\�Sϵ�y(t��ng)�c����Ganglia, Nagios
����������
��(sh��)��(j��)Ӌ��ģ�ͣ�����������̎��Storm, SparkStreaming
1. ����(sh��)��(j��)̎�푪�È����c����(sh��)��(j��)̎�������c
2. ����(sh��)��(j��)̎������Storm��ƽ�_�ܘ��c��Ⱥ����ԭ��
3. Storm�P�I���g�c���l(f��)�C��
4. Storm����ģ���c�����_�l(f��)ģʽ
5. Storm��(sh��)��(j��)���ֽM
6. Storm�ɿ��Ա��C�cAcker�C��
7. Storm���ð��������c���`��Storm��Ⱥ���b����Storm�����_�l(f��)�\�в������`��Storm�cHadoop��Ⱥ�ļ���
8. ����(sh��)��(j��)̎������Spark Streaming���������c��(sh��)��(j��)ģ��
9. Spark Streaming�����C��
��(sh��)��(j��)ETL�������ߣ��c��(sh��)��(j��)�ֲ�ʽ�ɼ�ϵ�y(t��ng)
1. Hadoop�cDBMS֮�g��(sh��)��(j��)�������ߵđ���
2. Sqoop���댧����(sh��)��(j��)�Ĺ���ԭ�����Լ�Sqoop���ߵİ��b�����c���`����������Sqoop���F(xi��n)MySQL�cHadoop��Ⱥ֮�g�Ĕ�(sh��)��(j��)���댧������
3. Flume-NG��(sh��)��(j��)�ɼ�ϵ�y(t��ng)�Ĕ�(sh��)��(j��)��ģ���cϵ�y(t��ng)�ܘ�
4. Kafka�ֲ�ʽ��Ϣӆ�ϵ�y(t��ng)�đ��ý�B�cƽ�_�ܘ�������ʹ��ģʽ
����������
����OLTP�͑��õ�NoSQL��(sh��)��(j��)�켰���Ì��`
1. �Pϵ�͔�(sh��)��(j��)��ƿ�i���Լ�NoSQL��(sh��)��(j��)��İl(f��)չ�������������ڰ�Y�����ͷǽY������(sh��)��(j��)�����µ��m�÷���
2. �д惦NoSQL��(sh��)��(j��)��HBase�����c��(sh��)��(j��)ģ������
3. HBase�ֲ�ʽ��Ⱥϵ�y(t��ng)�ܘ��c�x���C�ƣ�ZooKeeper�ֲ�ʽ�f(xi��)�{(di��o)����ϵ�y(t��ng)�Ĺ���ԭ���c����
4. HBase���OӋģʽ�cprimary key�OӋҎ(gu��)��
5. HBase�ֲ�ʽ��Ⱥ���b�������c�������`
6. �ęnNoSQL��(sh��)��(j��)��MongoDB�����c��(sh��)��(j��)ģ������
7. MongoDB��Ⱥģʽ���x���C���c����API����
8. Cassandra�ֲ�ʽ��(sh��)��(j��)���ƽ�_�ܘ��Լ��P�I���g
9. Cassandraһ���Թ�ϣ�㷨�c��(sh��)��(j��)�ֲ����ԣ��Լ�NWR����
10.�Iֵ��NoSQL��(sh��)��(j��)��Redis�����c��(sh��)��(j��)ģ������
11.Redis��������Ⱥ�ܘ��c�P�I���g
12.NewSQL��(sh��)��(j��)�켼�g���鼰���m�È���
��(sh��)��(j��)�Ŀ�x�͡���ʩ����(y��u)���Ȇ��}����ӑՓ ��(sh��)��(j��)�Ŀ��������������Ì�ʩ��ϵ�y(t��ng)��(y��u)�����Լ���Q��������ԃ�c����ӑՓ
������ �W�������c�I(y��)��(n��i)��(j��ng)��
�ġ����n���Y
��ώ� �F(xi��n)�����п�Ժij�о����������̎��������Q����ʿ���I(y��)���Ї��ƌWԺӋ�㼼�g�о������@���W��ʿ�Wλ��Ӌ��Cϵ�y(t��ng)�Y��������������Ĵ�(sh��)��(j��)����Ӌ�㡢�Ƅӻ�(li��n)�W(w��ng)ϵ���n�̽��O�c�̌W���ҡ�������펧�I�F���Ҫ���´�(sh��)��(j��)�c��Ӌ�㼼�g�Ŀ���аl(f��)�cIT�Ŀ������������ώ������������I(y��)��(n��i)Ӗ���_�n��Ӗ�v����(j��ng)�v����Ҫ�v�ڴ�(sh��)��(j��)ƽ�_���g����Ӌ�㡢�Ƅӻ�(li��n)�W(w��ng)������̄ա�IT��Ϣܛ���Ŀ��������I(y��)��Ϣ��Ҏ(gu��)���c������IT��(zh��n)��Ҏ(gu��)���c��I(y��)�ܘ�����(sh��)��(j��)�������CҎ(gu��)���cIDCϵ�y(t��ng)�\�I����I(y��)����(zh��n)���Ӗ�n�̡���ώ���ԭ�����g�����͑��Ì���(zh��n)��Y�ϵ����n�L���ܵ��V���_�n�W�T����I(y��)��(n��i)Ӗ�W�T�Ěgӭ��
�Y�ώ� ���A��W��ʿ����Ӌ�㌣�� ��Ϥ��������Ӌ��ƽ�_�������̘I(y��)�c�_Դ��Ӌ��ƽ�_�Č��`��(j��ng)�,����Ӌ���P�I���g������˽�͌��`��(j��ng)��ֲ�ʽϵ�y(t��ng)��̓�M�����ֲ�ʽ�ļ�ϵ�y(t��ng)���ƴ惦�ȣ����c���I������������Ӌ���Ŀ������(sh��)��(j��)�P�I���g������˽�͌��`��(j��ng)��NoSQL��(sh��)��(j��)�졢��(sh��)��(j��)̎����Hadoop��Hive��HBase��Spark�ȡ�
 �n�V���d
�n�V���d 

 ���T�c����
���T�c����